В процессе тестирования сайтов QA-специалист иногда встречается с необходимостью обозначить изучаемый объект в структуре сайта. Для этого можно использовать XPath – обсудим его в этой статье.
Что такое XPath?
Что такое XPath?
В процессе тестирования сайтов QA-специалист иногда встречается с необходимостью обозначить изучаемый объект в структуре сайта. Для этого можно использовать XPath – обсудим его в этой статье.

XPath в тестировании сайтов и веб-приложений
Ранее мы уже рассказывали о построении сайтов посредством HTML и других структурных языков. С их помощью тестировщик может создать структуру сайта и «оживить» его элементы для пользователя.
Как быть, если нужно идентифицировать один конкретный объект или несколько однотипных (например, если это может потребоваться для автоматизации тестирования)? Для этого можно использовать путь XPath. Давайте рассмотрим, что это такое.
DOM и XPath
Чтобы браузер, программы и скрипты могли считывать содержимое сайта, он должен быть структурирован. Один из способов такого структурирования – это представление в виде дерева. Корневым элементом является тег <html>, от него идут ветви – другие теги, а листьями являются конечные элементы контента. Такое построение называется DOM (англ. Document Object Model) — «объектная модель документа».
Для получения данных из DOM есть специальный язык запросов, который называется XPath. Он помогает находить нужный элемент в DOM и выделять его среди прочих.
Путь XPath
Код сайта в HTML таков, что одни теги входят в состав других. Получается вложенная структура. Путь XPath позволяет определять адрес каждого элемента. Например, если возьмем такой пример:

Тогда путь XPath к заголовку «Тестирование» будет следующим:
/html/head/titleПуть к заголовку «Тестирование сайта»:
/html/body/h1Путь к подзаголовку Роль HTML в сайтах»:
/html/body/h2Для чего применяется
Язык запросов XPath применяется в следующих прикладных задачах:
- Помогает программам считывать содержимое файлов формата HTML, также XHTML и XML;
- Позволяет скриптам, которые отвечают за обработку действий пользователя, находить нужный объект;
- Обеспечивает изменение контента и оформления веб-приложения;
- Дает возможность при необходимости менять структуру сайта;
- Помогает считывать данные с помощью запросов;
Все вышеуказанное позволяет производить тестирование в автоматизированном режиме – через запросы и выборку данных по исследуемым элементам. Например, с помощью инструмента Selenium.
Абсолютный и относительный путь: в чем разница
Есть две разновидности обозначения пути в XPath: абсолютный и относительный. Абсолютный (его еще называют полный путь) мы рассмотрели ранее – он начинается от корневого элемента <html> и по цепочке тегов ведет к одному конкретному элементу. В начале абсолютного пути ставится маркер «/», далее он же используется для разделения тегов.
Относительный путь в XPath начинается с маркера «//», а для разделения тегов, как и для абсолютного, используется знак «/». Например:
//body/h1В нашем примере это заголовок «Тестирование сайта». Но при этом относительный путь обозначает все объекты, которые в абсолютном пути имеют такое же выражение. Если бы у нас было несколько элементов с XPath, в котором есть //body/h1, то он бы относился к ним всем.
Относительный путь удобнее абсолютного, т.к. требуется меньше изменений в XPath, если кто-то поменял структуру всего сайта. Это удобно применять в автоматизированных тестах.
Как определить XPath элемента сайта
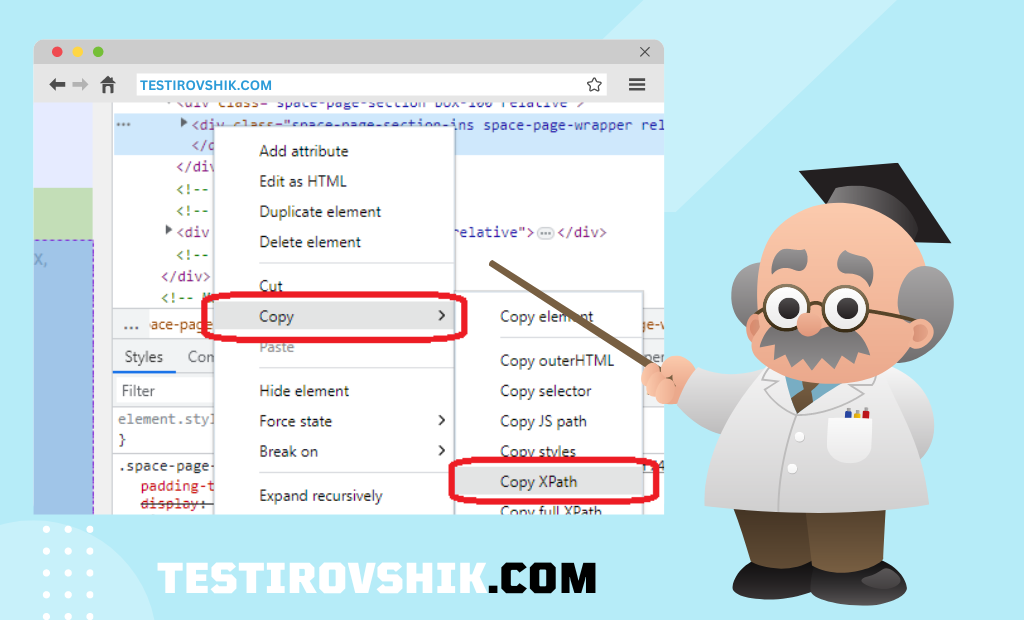
Самый простой способ определить XPath – это посмотреть его через инструмент разработчика в браузере. Что для этого нужно сделать по шагам:
- Навести мышку на нужный элемент, нажать правую клавишу и в выпадающем меню выбрать пункт «Посмотреть код элемента».

- Навести мышку на код выбранного элемента, нажать правую клавишу, в выпадающем меню выбрать «Copy», а затем «Copy XPath» (будет скопирован в буфер).
- Вставить скопированный XPath в любой документ, например, в блокнот или документ Word.

Резюме
XPath – язык запросов для элементов сайта. Он используется для обозначения элементов приложения и обработки его данных. XPath часто применяется при автоматизации тестирования.

Автор Михаил Кулешов
Михаил, профессиональный партнерский маркетолог, является основателем компании South Media OÜ, которая была создана в 2018 году и базируется в Таллинне. С 2016 года Михаил уехал из Финляндии и жил как настоящий «цифровой кочевник» в IT-индустрии, путешествуя по миру только с ноутбуком. Михаил работает и пишет статьи, связанные с IT-индустрией.


